

Featurethon - 3 The 14 Day JINA AI Challenge


I'm a Data Science enthusiast eager to keep myself updated on all new technologies. Featurethon is a 14-day learning challenge to develop a JINA AI-based application conducted by Featurepreneur. I'll be updating my progress on this blog.
DAY O -24/10/21
Orientation was conducted through zoom meetings organized by the Featurepreneur team.
Time spent = 1 hour
DAY 1 - 25/10/21
Learning - Differences between Symbolic search and Neural search.
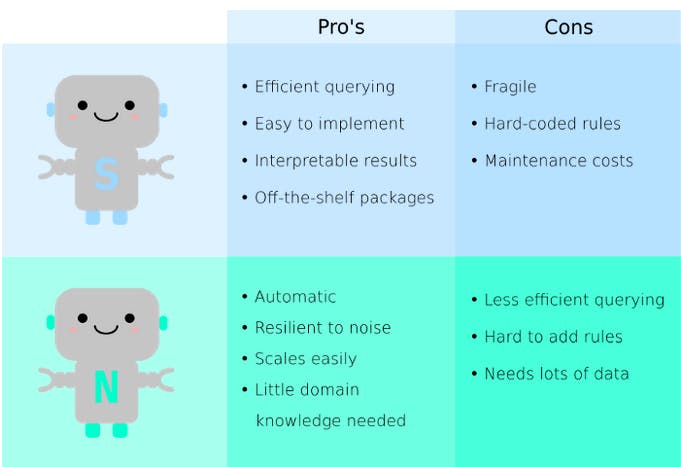
A symbolic search tells a machine a set of rules to understand what data is what, whereas neural search does the same thing but with a pre-trained neural network.
This means that there is no need to write every little rule, saving time and headaches for developers, and the system trains itself to get better as it goes along. Jina AI is an easier way to build scalable and sustainable neural search systems on the cloud.
Advantages of using Jina AI:
1)Easy to implement 2)offers anything-to-anything search
Time spent = 2.5 hours
DAY 2 - 26/10/21
What's a cross-modal search and a Multi-modal search.
A cross-modal search is like searching for matching titles for given paragraph text. a PDF file or an article has images and text together most of the time, In this case, we would have a file with multimodality: text and images. In order to have first-class support for cross and multi-modal search, Jina offers modality as an attribute from its Document protobuf definition.
I also installed JINA, which was pretty easy🙂.
!pip install jina
Time spent = 2.5 Hours
DAY 3 - 27/10/21
- Learning - Successfully ran hello world Demos .
- The three fundamental concepts in Jina are Document, Executor, and Flow.
*The document is the basic data type in Jina;
*An executor is how Jina processes Documents;
*Flow is how Jina streamlines and scales Executors.
- Started to scrape data for our own dataset using Selenium.
Time spent = 3 hours
DAY 4 - 28/10/21
Read more about:
- Executors -->These are the ones managing all the algorithmic parts, so there is no need to understand what happens under the hood. they can be connected to our Flow.
In Jina we have several Executors: 1) Crafter 2) Segmenter 3) Encoder 4) Indexer 5) Ranker 6) Classifier 7) Evaluator
CompoundExecutor --> Used to chain a pipeline of executors, where the input of the current is the output of the former. With this, we can use multiple executors at once.
Peas and Pods --> Jina Pea wraps an Executor and lets it exchange data with other Peas. Jina Pod is a context manager for one or multiple Peas that have the same properties.
If a Pod only contains only one Pea, we call it a Singleton Pod. If there is more than one Pea, Jina will add a HeadPea and TailPea to the same Pod. HeadPea distributes traffic to different Peas inside the Pod, TailPea collects the calculated result from the Peas inside the Pod. (Ex: if we want 3 Peas inside a pod, then there'll be 5 Peas inside that pod)
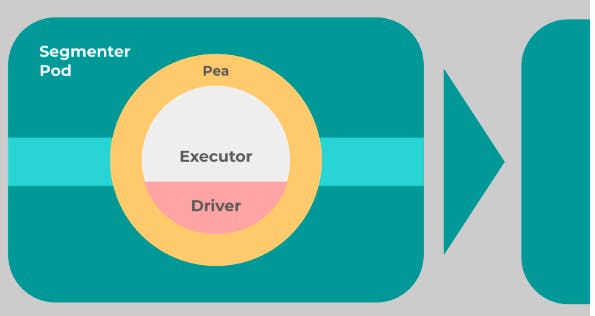
We use parallel to manage the number of stateless(Encoder, Crafter, Segmenter, etc.) Peas inside a Pod. We use shards to manage the number of stateful(Indexer) Peas inside a Pod.
Time spent = 4 hours
DAY 5 - 29/10/21
Scrapped data for our dataset and cleaned them, used selenium and Beautiful soup.
Flow -->Flow ties Executors together into a processing pipeline to perform a bigger task, like indexing or querying a dataset. Documents “flow” through the created pipeline and are processed by Executors.
Read about YAML basics -->YAML is a data-orientated human readable serialization language.
Had some errors while executing the Flow section of our code
Time spent = 3 hours
DAY 6 - 30/10/21
Understood the YAML syntax for Flow, Executor, CompoundExecutor, and Driver
Worked on the base code for our project and faced some errors, and tried resolving them.
Read about text summarization with Hugging Face transformers.
Collected data to our data set.
Time spent = 3 hours
DAY 7 - 31/10/21
YAML Intellisense support in Jina - Intellisense can provide code completion, syntax validation, argument filtering, default value filling, and help text display.
A Driver in Jina interprets incoming messages into Document and extracts required fields for an Executor.
Had an interactive session with other participants, where I came to know about them as well their creative ideas.😃
Time spent = 3 hours
DAY 8 -1/11/21
Crafter: It is used for pre-processing and the documents into chunks.
Ranker: It runs on the indexed storage and sorts the results based on a certain ranking.
Jina Box: Jina Box is an easy-to-use, lightweight, customizable front-end web component for data type agnostic search (be it text, audio, video, etc.) that can be easily connected to the Jina backend providing the user with a simple and efficient interface to interact with the search engine.
Time spent = 3 hours
DAY 9 -2/11/21
More data were added to our dataset.
Used our customized dataset in the base code for our project, came across some errors and warnings in the Flow section of the code.
Went through Jina AI docs and some YouTube videos, to resolve our error.
Time spent = 4 hours
DAY 10 - 3/11/21
- We replicated the same base code, but this time in a new environment OUTCOME: we were able to run the code without any errors, but had some warnings. also, we had to empty the Workspace.

Then we added some basic Flask components to our base code.😊
Also read about various ways to summarize a text
we tried using 4( T5, BART, GPT-2, XLNet) pre-trained models.
Time spent = 4 hours
DAY 11 - 4/11/21
REST DAY
- It was Diwali😇So we took a day off.🙂
Time spent = 0🙃
DAY 12 -5/11/21
We found some templates for our frontend part.
we saw some examples from Github.
we scrapped the text alone from an article link using BeatifulSoup, then later came across newspaper3k(python library for web scrapping), so we used newspaper3k to get the text from any article.
Time spent = 3 hours
DAY 13 - 6/11/21
using Jina, we were able to get the top5 links similar to the search query given, from our customized data set
also we made use of the T5 pre-trained model from Huggingface, to summarize the scrapped data(text from an article)
we made some changes to the Frontend part
Time spent = 4 hours
DAY 14 -7/11/21
- We completed our application for Featurethon Season 3
Artice Indexing and Text Summarization with Jina AI:
--> Give a keyword and the summary length, and the headlines of the articles are searched based on that keyword(from our customized dataset), and the top 5 article links are displayed by Jina AI neural search.
--> The topmost link is summarized by the pre-trained model(T5) from Huggingface, and it returns an extractive summary of the article.
-->The user gives a keyword and the summary length, In return, he gets the top 5 article links and an extractive summary is generated for the respective keyword entered by the user.
-->The Custom Dataset consists of scrapped articles(medium articles) related to cloud computing, machine learning, and deep learning using BeautifulSoup and Selenium.
By now we have successfully completed the 14-day learning challenge with Featurepreneur😀
Team Name: TechDuo
Team members: Ana Jessica & Ashwinkumar
Check out our Github Link:
github.com/ashwinchelsea14/article-indexing..
Demo Link:
Thanks for reading this blog🤗
Reference links: