



WEEK 3
When building a supervised machine-learning algorithm, the goal is to achieve low bias and variance for the most accurate predictions. Data scientists must do this while keeping underfitting and overfitting in mind. A model that exhibits small variance and high bias will underfit the target, while a model with high variance and little bias will overfit the target.
While training models on a dataset, the most common problems people face are overfitting and underfitting.
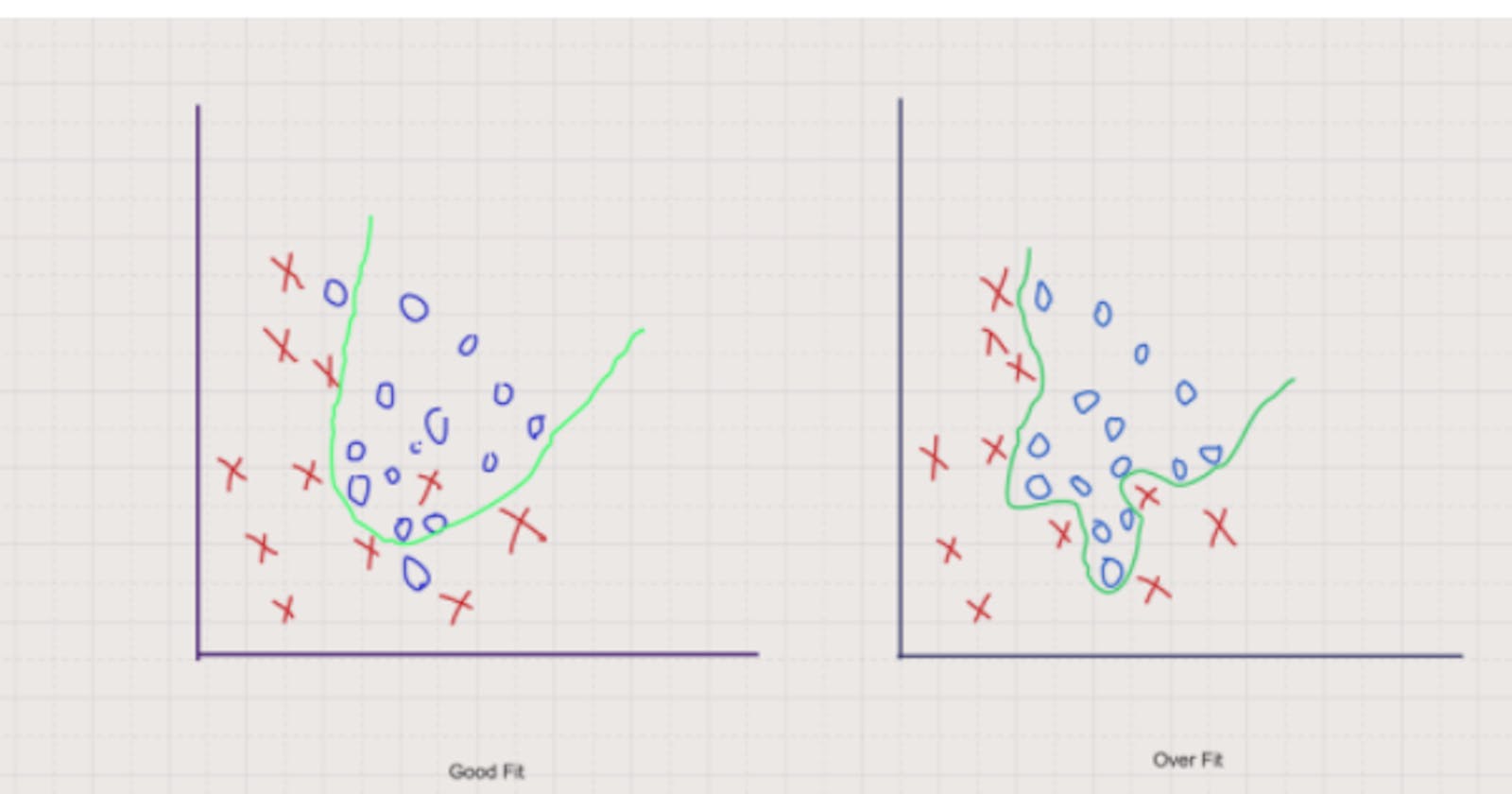
 Overfitting(right graph):
When a model learns the pattern of the data to such an extent that it hurts the performance of the model on the new dataset, is termed overfitting. The problem of overfitting mainly occurs with non-linear models whose decision boundary is non-linear.
Overfitting(right graph):
When a model learns the pattern of the data to such an extent that it hurts the performance of the model on the new dataset, is termed overfitting. The problem of overfitting mainly occurs with non-linear models whose decision boundary is non-linear.
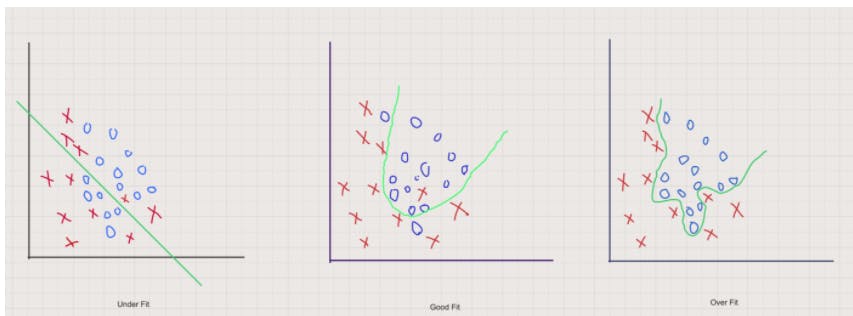
Underfitting(left graph): When the model neither learns from the training dataset nor generalizes well on the test dataset, it is termed as underfitting.
Good Fit(middle graph): The spot in the middle of underfitting and overfitting is a good fit.
We can prevent the model from overfitting by using techniques like K-fold cross-validation and hyperparameter tuning.
There are two main options to address the issue of overfitting:
1) Reduce the number of features:
Manually select which features to keep.
Use a model selection algorithm
2) Regularization
- Keep all the features, but reduce the magnitude of parameters θj
- Regularization works well when we have a lot of slightly useful features.
Regularization Intuition
It is mathematically seen that the high variance of a overfit hypothesis is attributed to the higher value of parameters corresponding to higher-order features i.e. more the dependency is biased on a single feature, the greater are the chances of a hypothesis overfitting. This effect can be counteracted by making sure that the values of the parameter θj are small. This is done by penalizing the algorithm proportional to the value of θj, which will ensure small values of these parameters and hence would prevent overfitting by attributing small contributions from each feature and hence removing high bias or high variance.

- The gradient descent for linear regression without regularization was given by,
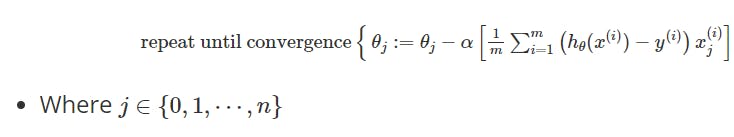
If we include the regularization term, there will be a change in the derivative of the cost function that was plugged in the gradient descent algorithm,
 it can be updated as,
it can be updated as,

- The gradient descent for logistic regression without regularization was given by,

it can be updated as,
